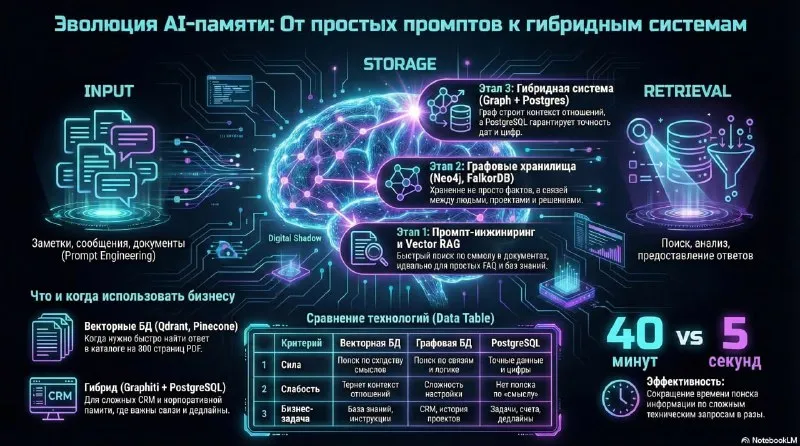
Practical AI-agent memory uses several stores. A vector database retrieves semantically similar documents, a graph connects people and events, and PostgreSQL keeps exact tasks, deadlines, and permissions.
I arrived at this design while building Digital Shadow. Qdrant retrieved fragments well, but operational context would not fit into separate collections.
Where vector memory fell short
My first design split memory into projects, partners, crypto, and personal records. In real work, one partner participates in several projects, a document relates to several decisions, and a personal conversation can affect business.
Data duplication and strict routing rules did not eliminate mistakes. A business meeting could enter personal memory, while a private topic could appear in a project collection. The data model caused the problem.
Qdrant describes the strength of vector search this way:
“Vector search retrieves information by semantic meaning, not just exact keyword matches.” — Qdrant Documentation
Source: Qdrant vector search overview
Semantic similarity helps with documentation, FAQs, manuals, and meeting fragments. Related context may require a chain: person → project → meeting → decision → deadline → document.
Why operational context looks like a graph
A company stores relationships: who attended a meeting, which project it concerned, what they promised, and which decision depended on another.
In a graph model, a person connects to a project, the project to a document, the document to a risk, the risk to a task, and the task to a deadline.
Neo4j describes this model through nodes and relationships:
“Nodes represent entities or discrete objects in a domain. Relationships represent a connection between a source node and a target node.” — Neo4j Documentation
Source: Neo4j graph database concepts
A graph answers questions that require relationship traversal: what the team promised a client after a meeting, why it chose a stack, or which decisions depend on supplier X.
What changed in Digital Shadow
I use Graphiti and FalkorDB for graph memory and PostgreSQL for exact entities. An evening reflection becomes episodes, facts, and relationships among people, projects, decisions, and state changes.
Graphiti calls this structure a Context Graph, a temporal graph of entities, relationships, and facts.
“Graphiti helps you create and query Context Graphs that evolve over time.” — Graphiti Documentation
Source: Graphiti Context Graph overview
Time matters. A partner changes roles, a project closes, a deadline moves, and a contract gets a new version. The graph has to preserve that history.
FalkorDB serves as the graph database in the current design. Documentation: FalkorDB
The role of PostgreSQL
Tasks, deadlines, statuses, users, permissions, and settings need exact answers. A similar memory or probabilistic explanation is unsafe for this data.
PostgreSQL provides foreign keys, transactions, triggers, views, and transactional integrity. Those properties support verifiable changes and operational logs.
Source: What is PostgreSQL?
The LLM explains data, vector search retrieves documents, and the graph exposes relationships. The current task status stays in a transactional table.
When memory becomes excessive
After the move to a graph, the assistant started returning too much context. A question about one partner could retrieve several screens of projects, meetings, agreements, decisions, and documents.
I added priorities and response modes. The default answer stays short, deeper history appears on request, recent facts rank above older ones, and decisions rank above background observations.
The stores preserve information, while a policy layer controls how much reaches the answer.
A working memory design
- A vector database stores documents, notes, and meeting fragments for semantic search.
- A graph database connects people, projects, companies, decisions, and events.
- PostgreSQL stores tasks, deadlines, statuses, permissions, settings, and logs.
- An LLM reasons over and explains the retrieved context.
- A policy layer sets access, priority, freshness, and visibility.
The hybrid design is more complex than one vector store because it reflects the structure of real work. Business context consists of documents, people, decisions, deadlines, and the relationships among them.