Useful AI work starts with three decisions: select a model for the job, give it relevant context, and end a conversation once its history becomes noise. A weak result often points back to one of those choices.
Why a model gives a weak answer
A typical request says, “make me a strategy.” The model knows nothing about the company, constraints, required format, or facts it must avoid inventing, so it returns generic prose.
A language model works with the input it receives. It cannot reconstruct hidden business context on its own.
Most failures begin in one of three places:
- the model is a poor fit for the task;
- the request lacks essential inputs;
- the chat contains old versions, contradictions, and missing instructions.
This article covers model selection and context. A separate article treats the prompt as a practical task brief.
Different models suit different work
An abstract ranking of “good” and “bad” models is rarely useful. Comparing them on real tasks and a stable set of evaluation examples gives a better answer.
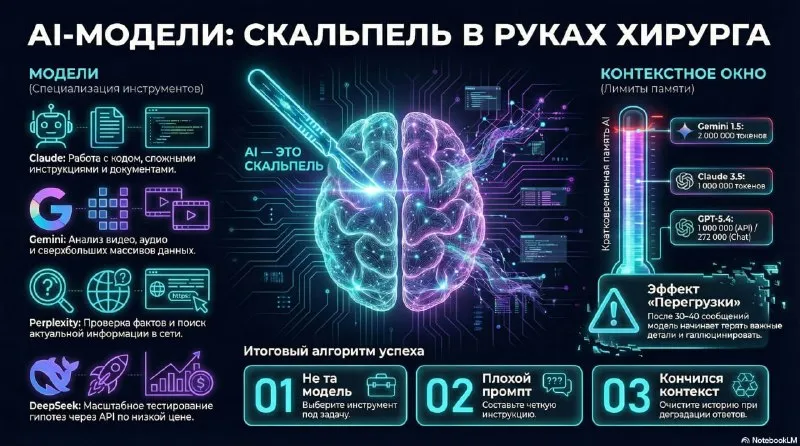
Claude handles code, long documents, architecture reviews, and complex instructions in my workflow. Its response structure works well for the longer tasks I run.
Gemini is useful for large inputs such as documents, meeting recordings, video, audio, and extensive reports. Google gave Gemini 1.5 Pro developers access to a context window of up to 2 million tokens.
“Today, we’re opening up access to the 2 million token context window on Gemini 1.5 Pro for all developers.” — Google Developers Blog
Source: Google Developers Blog, Gemini API and Google AI Studio
A large window does not automatically improve a model's reasoning. It allows more source material in one request when that material is selected and structured well.
Perplexity serves as a first-pass search tool in my process. It helps build a source map, after which important claims still need to be checked against primary sources.
Qwen and other local models can serve work where internal documents, drafts, or personal context must stay in a controlled environment. The right option depends on quality targets, infrastructure, and data protection requirements.
DeepSeek API and other low-cost API models can fit bulk classification, preliminary data processing, and repeated hypothesis checks. The useful measures here are cost across many runs and tested quality, rather than one impressive response.
ChatGPT works well for many teams, although it was not my primary tool for complex instructions for a long time. Evaluate a model on your own work instead of choosing a side in a general online debate.
What a context window contains
A context window contains the information available for the current request: messages, system instructions, files, document fragments, and search results. It resembles short-term memory, with a key distinction: the model receives the input again and generates its next response from the data included there.
Google described the scale of Gemini 1.5's long context this way:
“This means 1.5 Pro can process vast amounts of information in one go — including 1 hour of video, 11 hours of audio, codebases with over 30,000 lines of code or over 700,000 words.” — Google Blog
Source: Google Blog, Gemini 1.5
Long context is useful when a task needs a relevant body of material and a specific question. An endless conversation lasting several weeks creates a separate problem by accumulating outdated requirements and unrelated comments.
Why long chats lose quality
After 30 or 40 messages, a conversation may contain old solution versions, cancelled requirements, and fragments that no longer belong to the task. The model still receives them as part of its input.
Once the window is full, a product may trim or summarize the history. Users usually cannot see which instruction disappeared or which constraint stopped influencing the answer.
My working rule is one chat per task. If a conversation starts to drift, I ask for a concise decision summary, review it, and continue in a fresh chat.
Business examples
Meeting preparation. Client messages, earlier decisions, open questions, and documents become a short brief, a risk list, and questions for the meeting.
Document work. A model drafts a contract, proposal, partner email, or technical brief faster when it receives a template, inputs, constraints, and output format.
Analysis. AI can provide an initial structure for a report, table, market study, or customer feedback set. Figures and conclusions still require source checks.
Prototyping. A product idea can become an MVP outline, user scenarios, risks, and a list of questions to resolve before development.
A reliable working process
- Choose the model for the input type: code, documents, search, or local data.
- Provide source material instead of asking the model to infer missing context.
- State quality criteria and the output format in advance.
- Keep unrelated tasks in separate chats.
- Verify facts and request sources for claims about the external world.
- Store reusable knowledge in RAG, a knowledge base, or project memory.
Anthropic's documentation makes clear that another prompt is not the answer to every quality problem:
“Not every success criteria or failing eval is best solved by prompt engineering.” — Anthropic Claude Docs
Source: Anthropic Claude Docs, Prompt engineering overview
When a model repeatedly fails on a task, review the tool, the available context, its data integrations, and the evaluation method. Rewriting the request helps only when the request is the actual cause.
AI becomes a professional tool when a team deliberately chooses the model, prepares the context, limits the task, and verifies the result. Those habits matter more than the search for a universal “magic prompt.”