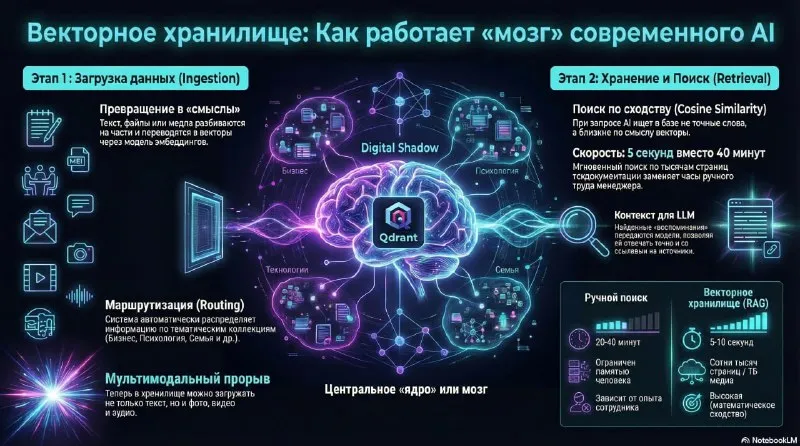
RAG solves a practical problem: it finds an answer in a large document set and shows the sources. When a company has hundreds of PDFs, catalogs, manuals, contracts, and FAQs, keyword search often requires manual verification. Semantic retrieval gives the model fragments related by meaning.
Where business value appears
Consider a company that sells industrial equipment. A customer needs a 12-bar compressor for a line producing 200 units per hour, and the equipment has to fit inside a 3 by 4 meter room.
Without RAG, a manager opens catalogs, compatibility tables, and datasheets. A RAG system indexes the documentation in advance, retrieves relevant fragments, and prepares an answer with links to exact pages or sections.
A new employee can locate the right parameters faster, engineers spend less time on repeated questions, and the customer receives a verifiable answer.
Qdrant explains semantic search with a simple example:
“A search for ‘climate change’ can retrieve documents about ‘global warming,’ even if the exact words differ.” — Qdrant Documentation
Source: Qdrant overview
A customer may ask whether a unit fits in a small room while the datasheet lists dimensions of 1180 × 760 × 940 mm. The wording differs, but both descriptions refer to a related property.
How RAG works
RAG stands for retrieval-augmented generation. The system retrieves suitable documents first, then asks an LLM to prepare an answer from that context.
A minimal workflow has six steps:
- Documents are split into pages, sections, paragraphs, or tables.
- An embedding model turns each fragment into a numerical representation of meaning.
- A vector database stores vectors and metadata such as file, page, version, product, and date.
- The user query becomes a vector too.
- The database returns the top-k nearest fragments.
- The LLM prepares an answer and cites its sources.
The original RAG paper describes a combination of parametric and non-parametric memory:
“RAG models combine parametric memory with non-parametric memory.” — Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Source: Lewis et al. paper on RAG
General knowledge stays in the model parameters, while company facts live in an external database that teams can update. A changed catalog or manual requires re-indexing instead of training a new LLM.
How to choose the database
I use Qdrant for semantic search in Digital Shadow. Another project may need a different option:
- Qdrant supports self-hosted deployment, hybrid search, and straightforward operations;
- Weaviate provides an open-source vector database and tools for semantic search and RAG;
- Pinecone fits teams that prefer a managed service;
- PostgreSQL with pgvector can handle a moderate data set when Postgres already runs in the stack.
The choice depends on SLA, data volume, security, the cost of an error, and maintenance capacity. No database wins for every project.
Documentation: Weaviate, Pinecone
Where RAG fails
Outdated documents, poor chunking, and contradictory versions create weak context. The model may confidently summarize a retrieved error. Without source and version metadata, the team cannot reconstruct why it produced that answer.
Common implementation mistakes include:
- ingesting PDFs without cleaning tables and headings;
- making chunks too large or too small;
- omitting version, date, product, language, and owner metadata;
- evaluating the final answer without testing retrieval separately;
- providing no “insufficient evidence” response for weak sources.
Weaviate describes its role in a RAG workflow this way:
“Weaviate can serve as a robust backend for RAG workflows, where vector search is used to retrieve context that enhances the output of generative models.” — Weaviate Documentation
RAG supplies working context to the model. A production pipeline includes ingestion, retrieval, reranking, answer generation, citations, and feedback. Teams need a quality measure at every stage.
When a vector database is excessive
Ten short documents may fit directly inside the model context. A direct upload or conventional search is simpler in that case.
RAG becomes useful with hundreds of documents, recurring questions, a high error cost, several user roles, and required source citations. Its economic effect comes from saved search time and prevented mistakes.