AI without memory makes people explain a project again in every new conversation. That is annoying in personal work. In a company, repeated context gathering consumes time, loses agreements, and leads teams back to solutions they already tried.
I added vector memory to Digital Shadow. The agent now retrieves related projects, partners, files, decisions, and mistakes before it prepares an answer.
Where the context disappeared
The same scenario kept recurring. I explained a project, closed the chat, and returned the next day. Then I had to describe the partner, architecture, deadline, and failed approach again.
The chat retained one conversation, while working context lasted much longer. The system needed a separate memory layer to bring that context back.
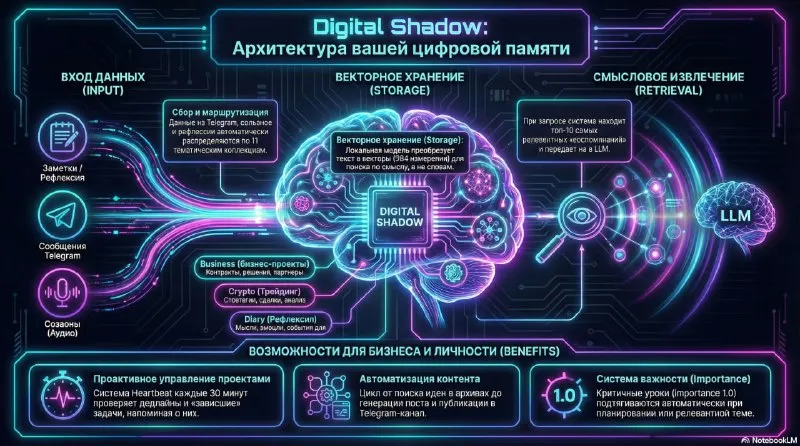
How vector memory works
I send Digital Shadow thoughts, meeting notes, messages, and decisions. The system organizes them into collections. When I ask a question, it runs semantic search and places the most relevant records in the model context.
This process follows the idea of RAG, or retrieval-augmented generation. In the Lewis et al. paper, a generative model receives external, non-parametric memory through document retrieval.
“RAG models combine pre-trained parametric and non-parametric memory for language generation.” — Lewis et al., 2020
Source: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
The model does not have to keep every fact in its parameters. It can retrieve suitable records from an external store before answering.
Case 1: a partner call
A partner sends a project brief and schedules a call one week later. Digital Shadow retrieves a short summary of the project, timeline, previous discussion, and known risks.
I do not have to search the chat or ask for the details again. Preserved agreements save time and support trust.
Case 2: returning to an older project
Details blend together when several projects run in parallel. An older project can return one month later with an urgent question.
The system assembles a brief with architecture, tokens, deadlines, owners, and earlier decisions. I can re-enter the task with the relevant context already available.
Case 3: remembering failed decisions
The memory of a failed decision can be more valuable than a general summary. If technology X failed in production for a known reason, the agent can retrieve that episode during a similar choice.
The reminder cannot guarantee a correct decision. It reduces the chance of repeating a mistake after the team has forgotten the details.
What RAG gives a company
IBM Research describes RAG as a way to ground LLM responses in external knowledge and improve their accuracy and freshness.
“RAG is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge.” — IBM Research
Source: IBM Research explanation of RAG
Agent memory creates several practical effects:
- agreements stay connected to their project;
- people repeat fewer background details;
- teams return to older work faster;
- decision history helps review recurring mistakes;
- roles can control access to company knowledge.
Memory limits
Memory does not remove model errors. A poor record creates poor context, an oversized chunk blurs meaning, and excessive permissions can expose sensitive data.
The store needs structure, cleanup, source links, logs, and access rules. In the first Digital Shadow version, this layer uses a vector database, local embeddings, collections, and rules that control which records appear.