Польза от AI начинается с трёх решений: выбрать модель под задачу, передать ей нужный контекст и вовремя завершить перегруженный чат. Слабый результат часто указывает на ошибку в одном из этих решений.
Почему модель даёт слабый ответ
Типичный запрос звучит как «сделай мне стратегию». Модель не знает устройство компании, ограничения, желаемый формат и факты, которые нельзя выдумывать, поэтому возвращает общий текст.
Языковая модель работает с тем входом, который получила. От неё нельзя ожидать, что она сама восстановит скрытый бизнес-контекст.
Обычно причина находится в одном из трёх мест:
- модель плохо подходит для задачи;
- запрос не содержит достаточных вводных;
- история чата переполнена старыми версиями, противоречиями и потерянными инструкциями.
Эта статья посвящена выбору модели и подготовке контекста. Отдельный материал разбирает промпт как рабочее техническое задание.
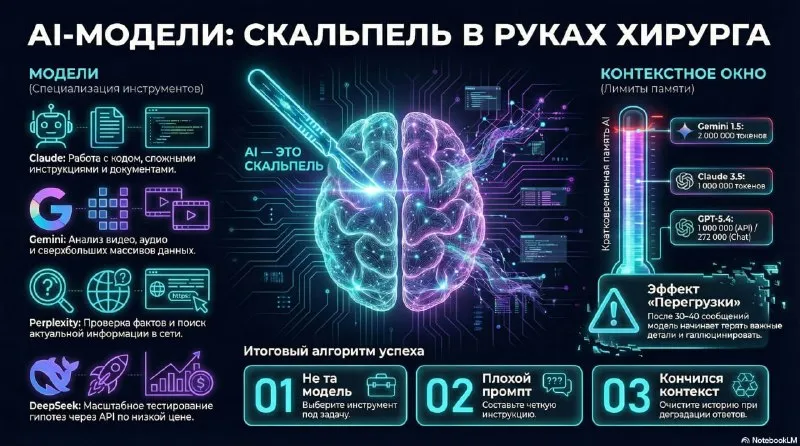
Модели решают разные задачи
Абстрактного рейтинга «хороших» и «плохих» моделей недостаточно. Полезнее сравнивать их на конкретной работе и собственных проверочных примерах.
Claude в моём рабочем процессе используется для кода, длинных документов, архитектурных разборов и сложных инструкций. На таких задачах мне удобно работать с его структурой ответа.
Gemini подходит для больших входных данных: документов, записей встреч, видео, аудио и объёмных отчётов. Google открыл разработчикам Gemini 1.5 Pro контекстное окно до 2 млн токенов.
“Today, we’re opening up access to the 2 million token context window on Gemini 1.5 Pro for all developers.” — Google Developers Blog
Источник: Google Developers Blog, Gemini API and Google AI Studio
Большое окно не повышает интеллект модели автоматически. Оно позволяет передать больше исходных данных за один запрос, если эти данные отобраны и структурированы.
Perplexity я использую для первичного поиска со ссылками. Результат помогает построить карту источников, после чего важные факты нужно сверить с первоисточниками.
Qwen и другие локальные модели подходят для сценариев, где внутренние документы, черновики или персональный контекст должны оставаться в контролируемой среде. Конкретный выбор зависит от требований к качеству, инфраструктуре и защите данных.
DeepSeek API и другие недорогие API-модели могут быть полезны для массовой классификации, предварительной обработки данных и проверки гипотез. Здесь важны стоимость серии прогонов и измеримое качество, а не впечатление от одного ответа.
ChatGPT удобен многим командам, хотя в моём стеке долго не был основным инструментом для сложных инструкций. Модель следует проверять на собственных задачах, а не выбирать по общему спору в интернете.
Что хранит контекстное окно
Контекстное окно содержит информацию, доступную модели в текущем запросе: сообщения, системные инструкции, файлы, фрагменты документов и результаты поиска. Его можно сравнить с кратковременной памятью, но модель каждый раз получает вход заново и строит следующий ответ из попавших в него данных.
В первом анонсе Gemini 1.5 Google описывал возможности длинного контекста так:
“This means 1.5 Pro can process vast amounts of information in one go — including 1 hour of video, 11 hours of audio, codebases with over 30,000 lines of code or over 700,000 words.” — Google Blog
Источник: Google Blog, Gemini 1.5
Длинный контекст нужен для релевантного массива материалов и конкретного вопроса. Бесконечный чат на несколько недель создаёт другую проблему: в истории накапливаются устаревшие требования и случайные уточнения.
Почему длинный чат теряет качество
После 30–40 сообщений в диалоге могут одновременно остаться старые версии решения, отменённые требования и фрагменты, которые уже не относятся к задаче. Модель всё равно получает их как часть входа.
При заполнении окна продукт может обрезать или сжать историю. Пользователь обычно не видит, какая инструкция исчезла и какое ограничение перестало учитываться.
Моё рабочее правило: один чат обслуживает одну задачу. Если диалог начал отклоняться, я прошу составить краткое резюме решений, проверяю его и продолжаю в новом чате.
Примеры для бизнеса
Подготовка к встрече. История переписки, прежние решения, открытые вопросы и документы превращаются в краткую справку, список рисков и вопросы собеседнику.
Работа с документами. Модель быстрее готовит черновик договора, коммерческого предложения, письма или технического задания, когда получает шаблон, вводные, ограничения и формат результата.
Аналитика. AI помогает первично разобрать отчёт, таблицу, исследование рынка или обратную связь клиентов. Выводы и цифры затем проверяются по источникам.
Прототипирование. Описание идеи можно превратить в структуру MVP, пользовательские сценарии, риски и перечень вопросов до начала разработки.
Устойчивый рабочий процесс
- Выбирайте модель по типу входа: код, документы, поиск или локальные данные.
- Передавайте исходные материалы вместо просьбы угадать контекст.
- Заранее задавайте критерии качества и формат ответа.
- Разделяйте разные задачи по чатам.
- Проверяйте факты и запрашивайте ссылки для данных о внешнем мире.
- Повторно используемые знания храните в RAG, базе знаний или проектной памяти.
Anthropic отдельно предупреждает, что новый промпт решает не каждую проблему с качеством:
“Not every success criteria or failing eval is best solved by prompt engineering.” — Anthropic Claude Docs
Источник: Anthropic Claude Docs, Prompt engineering overview
Если модель регулярно ошибается на задаче, стоит проверить сам инструмент, состав контекста, интеграцию с данными и способ оценки. Переформулировка запроса полезна только тогда, когда причина действительно находится в запросе.
AI становится рабочим инструментом, когда команда осознанно выбирает модель, готовит контекст, ограничивает задачу и проверяет результат. Эти привычки дают больше, чем поиск универсального «волшебного промпта».