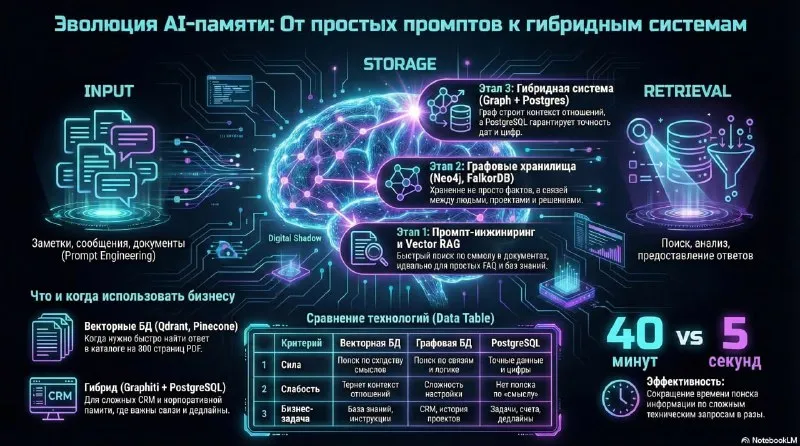
Практичная память AI-агента состоит из нескольких хранилищ. Векторная база находит похожие по смыслу документы, граф связывает людей и события, а PostgreSQL хранит точные задачи, сроки и права.
Я пришёл к этой схеме в Digital Shadow. Qdrant хорошо находил фрагменты, но операционный контекст не помещался в отдельные коллекции.
Где векторной памяти стало мало
Сначала я разделил память на проекты, партнёров, крипту и личные записи. В реальной работе один партнёр участвует в нескольких проектах, документ относится к разным решениям, а личный разговор может повлиять на бизнес.
Дублирование данных и строгие правила маршрутизации не устранили ошибки. Бизнес-встреча попадала в личную коллекцию, а личная тема могла оказаться в памяти проекта. Причина находилась в модели данных.
Qdrant формулирует сильную сторону векторного поиска так:
“Vector search retrieves information by semantic meaning, not just exact keyword matches.” — Qdrant Documentation
Источник: Qdrant vector search overview
Семантическая близость помогает искать документацию, FAQ, инструкции и фрагменты встреч. Связанный контекст требует цепочки: человек → проект → встреча → решение → дедлайн → документ.
Почему операционный контекст похож на граф
Компания хранит отношения: кто участвовал во встрече, к какому проекту она относилась, что было обещано и какое решение зависело от другого.
В графовой модели человек связан с проектом, проект с документом, документ с риском, риск с задачей, а задача с дедлайном.
Neo4j описывает эту модель через nodes и relationships:
“Nodes represent entities or discrete objects in a domain. Relationships represent a connection between a source node and a target node.” — Neo4j Documentation
Источник: Neo4j graph database concepts
Граф отвечает на вопросы, в которых нужен обход связей: что команда обещала клиенту после встречи, почему выбрала стек или какие решения зависят от поставщика X.
Что изменилось в Digital Shadow
Для графовой памяти я использую Graphiti и FalkorDB, а точные сущности храню в PostgreSQL. Вечерняя рефлексия превращается в эпизоды, факты и связи: упомянутых людей, проекты, решения и изменения состояния.
Graphiti называет такую структуру Context Graph, то есть временной граф сущностей, отношений и фактов.
“Graphiti helps you create and query Context Graphs that evolve over time.” — Graphiti Documentation
Источник: Graphiti Context Graph overview
Время здесь имеет значение. Партнёр меняет роль, проект закрывается, дедлайн переносится, а договор получает новую версию. Граф должен сохранять историю этих изменений.
FalkorDB выступает графовой базой в текущей схеме. Документация: FalkorDB
Роль PostgreSQL
Задачи, сроки, статусы, пользователи, права и настройки требуют точного ответа. Для них похожее воспоминание или вероятностное объяснение не подходит.
PostgreSQL даёт foreign keys, транзакции, triggers, views и transactional integrity. Эти свойства позволяют проверять изменения и вести операционный журнал.
Источник: What is PostgreSQL?
LLM объясняет данные, векторный поиск находит документы, а граф показывает связи. Текущий статус задачи остаётся в транзакционной таблице.
Когда памяти становится слишком много
После перехода на граф ассистент начал возвращать слишком широкий контекст. Вопрос о партнёре мог поднять проекты, встречи, договорённости, решения и документы на несколько экранов.
Я добавил приоритеты и режимы ответа. По умолчанию система показывает короткий контекст, по запросу раскрывает детали, свежие факты ставит выше старых, а решения отделяет от фоновых наблюдений.
Хранилище отвечает за полноту, а policy layer дозирует выдачу.
Рабочая схема памяти
- Векторная база хранит документы, заметки и фрагменты встреч для поиска по смыслу.
- Графовая база связывает людей, проекты, компании, решения и события.
- PostgreSQL хранит задачи, дедлайны, статусы, права, настройки и журналы.
- LLM рассуждает и объясняет найденный контекст.
- Policy layer задаёт доступ, приоритет, свежесть и видимость данных.
Гибридная схема сложнее одного векторного хранилища, потому что отражает реальную структуру работы. Бизнес-контекст складывается из документов, людей, решений, сроков и связей между ними.