AI без памяти заставляет заново объяснять проект при каждом новом диалоге. В личной работе это раздражает. В компании повторный сбор контекста отнимает время, стирает договорённости и приводит к повторению старых решений.
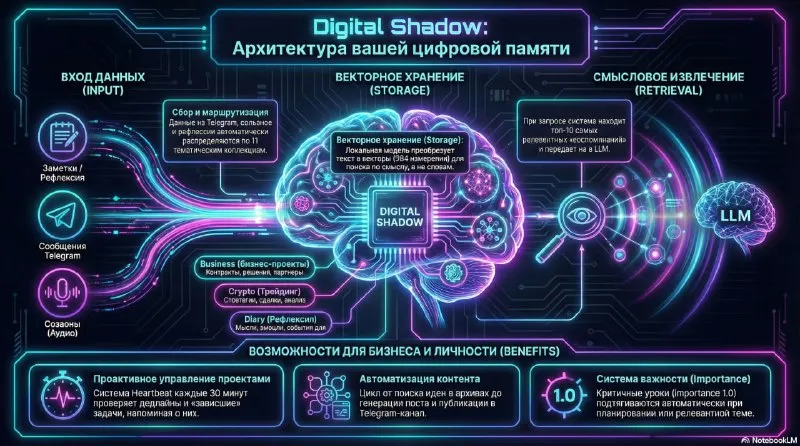
Я добавил в Digital Shadow векторную память. Теперь агент ищет связанные проекты, партнёров, файлы, решения и ошибки перед подготовкой ответа.
Где терялся контекст
Сценарий повторялся регулярно: я рассказывал системе о проекте, закрывал чат и возвращался на следующий день. Приходилось снова объяснять, кто партнёр, как устроена архитектура, где дедлайн и почему прошлый подход не сработал.
Чат сохранял текущий разговор, но рабочий контекст жил дольше одной сессии. Для его возврата системе понадобился отдельный слой памяти.
Как работает векторная память
Я отправляю в Digital Shadow мысли, итоги встреч, сообщения и решения. Система распределяет записи по коллекциям. Во время вопроса она выполняет семантический поиск и добавляет наиболее связанные фрагменты в контекст модели.
Этот процесс близок к RAG, или retrieval-augmented generation. В работе Lewis et al. генеративная модель получает внешнюю непараметрическую память через поиск документов.
“RAG models combine pre-trained parametric and non-parametric memory for language generation.” — Lewis et al., 2020
Источник: Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Модели не требуется хранить все факты в своих параметрах. Перед ответом она получает подходящие записи из внешнего хранилища.
Кейс 1: разговор с партнёром
Партнёр присылает техническое задание, а через неделю назначает звонок. Digital Shadow возвращает краткий контекст: проект, сроки, прошлое обсуждение и отмеченные риски.
Мне не приходится искать переписку или просить повторить детали. Сохранённые договорённости экономят время и поддерживают доверие.
Кейс 2: возвращение к старому проекту
При нескольких параллельных проектах детали быстро смешиваются. Старый проект может вернуться через месяц с новым срочным вопросом.
Система собирает короткую справку об архитектуре, токенах, сроках, ответственных и прошлых решениях. Так вход в задачу начинается с актуального контекста.
Кейс 3: история неудачных решений
Память о неудаче часто ценнее общей справки. Если технология X упала в production по известной причине, агент может найти этот эпизод во время похожего выбора.
Напоминание не гарантирует правильное решение. Оно снижает вероятность повторить ошибку после того, как команда забыла детали.
Что RAG даёт компании
IBM Research описывает RAG как способ связать ответ LLM с внешними источниками знаний и повысить его точность и актуальность.
“RAG is an AI framework for improving the quality of LLM-generated responses by grounding the model on external sources of knowledge.” — IBM Research
Источник: объяснение RAG от IBM Research
Рабочая память агента даёт несколько практических эффектов:
- договорённости остаются связанными с проектом;
- людям реже приходится повторять вводные;
- команда быстрее возвращается к старым задачам;
- история решений помогает разбирать повторные ошибки;
- доступ к знаниям можно контролировать по ролям.
Ограничения памяти
Память не устраняет ошибки модели. Плохая запись создаёт плохой контекст, слишком крупный фрагмент размывает смысл, а лишние права могут раскрыть чувствительные данные.
Поэтому хранилищу нужны структура, очистка, ссылки на источники, журналы и правила доступа. В первой версии Digital Shadow это практический слой из векторной базы, локальных эмбеддингов, коллекций и правил выдачи записей.