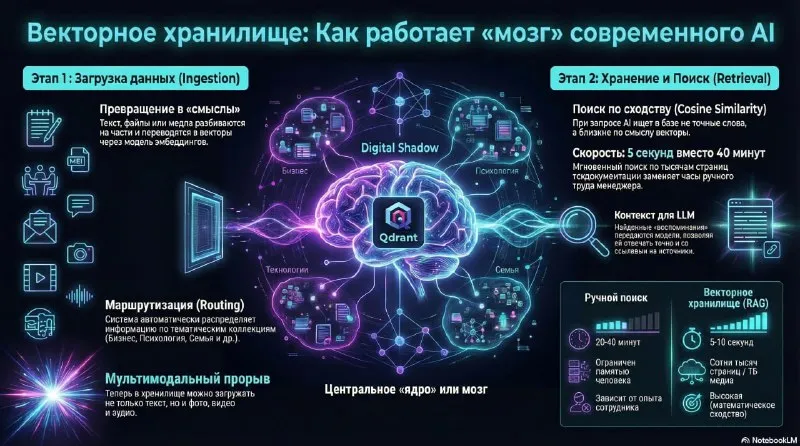
RAG решает практическую задачу: находит ответ в большом массиве документов и показывает источники. Когда у компании сотни PDF, каталогов, инструкций, договоров и FAQ, поиск по словам часто требует ручной проверки. Семантический поиск возвращает модели связанные фрагменты по смыслу.
Где появляется бизнес-ценность
Представим компанию, которая продаёт промышленное оборудование. Клиенту нужен компрессор на 12 бар для линии на 200 единиц в час, а оборудование должно поместиться в комнате 3 на 4 метра.
Менеджер без RAG открывает каталоги, таблицы совместимости и техпаспорта. Система с RAG заранее индексирует документы, находит связанные фрагменты и готовит ответ со ссылками на страницы или разделы.
Так новый сотрудник быстрее находит нужные параметры, инженеры реже отвлекаются на повторяющиеся вопросы, а клиент получает проверяемый ответ.
Qdrant объясняет семантический поиск на простом примере:
“A search for ‘climate change’ can retrieve documents about ‘global warming,’ even if the exact words differ.” — Qdrant Documentation
Источник: обзор Qdrant
Клиент может сказать «поместится в маленькую комнату», а в документации будут указаны габариты 1180 × 760 × 940 мм. Формулировки отличаются, но описывают связанную характеристику.
Как работает RAG
RAG расшифровывается как retrieval-augmented generation. Система сначала получает подходящие документы, затем просит LLM подготовить ответ по найденному контексту.
Минимальный процесс выглядит так:
- Документы делятся на страницы, разделы, абзацы или таблицы.
- Embedding-модель превращает каждый фрагмент в числовое представление смысла.
- Векторная база хранит векторы и метаданные: файл, страницу, версию, продукт и дату.
- Запрос пользователя тоже превращается в вектор.
- База возвращает top-k ближайших фрагментов.
- LLM формирует ответ и указывает источники.
Исходная работа по RAG описывает сочетание параметрической и непараметрической памяти:
“RAG models combine parametric memory with non-parametric memory.” — Lewis et al., Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks
Источник: работа Lewis et al. о RAG
Общие знания остаются в параметрах модели, а факты компании хранятся во внешней обновляемой базе. При изменении каталога или инструкции команда переиндексирует документы без обучения новой LLM.
Как выбрать хранилище
В Digital Shadow я использую Qdrant для семантического поиска. Другому проекту может подойти иной вариант:
- Qdrant поддерживает self-hosted развёртывание, гибридный поиск и понятную эксплуатацию;
- Weaviate предлагает open-source vector database и инструменты для semantic search и RAG;
- Pinecone подходит командам, которым нужен managed-сервис;
- PostgreSQL с pgvector может закрыть умеренный объём, если Postgres уже работает в инфраструктуре.
Выбор зависит от SLA, объёма данных, модели безопасности, цены ошибки и ресурсов на поддержку. Универсально лучшей базы для всех проектов нет.
Документация: Weaviate, Pinecone
Где RAG ошибается
Старые документы, плохая нарезка и противоречивые версии создают слабый контекст. Модель может уверенно пересказать найденную ошибку. Без источника и версии команда не сможет восстановить причину ответа.
Частые ошибки внедрения:
- загрузка PDF без очистки таблиц и заголовков;
- слишком крупные или слишком мелкие фрагменты;
- отсутствие версии, даты, продукта, языка и владельца в metadata;
- оценка финального ответа без отдельной проверки retrieval;
- отсутствие ответа «данных недостаточно» при слабых источниках.
Weaviate описывает свою роль в RAG так:
“Weaviate can serve as a robust backend for RAG workflows, where vector search is used to retrieve context that enhances the output of generative models.” — Weaviate Documentation
RAG даёт модели рабочий контекст. Production-процесс включает ingestion, retrieval, reranking, answer, citations и feedback. Качество нужно измерять на каждом этапе.
Когда векторная база избыточна
Десять коротких документов могут целиком поместиться в контекст модели. В таком случае достаточно прямой загрузки файлов или обычного поиска.
RAG становится полезен при сотнях документов, регулярных вопросах, высокой цене ошибки, нескольких ролях и обязательных ссылках на источники. Экономический эффект складывается из времени ручного поиска и числа предотвращённых ошибок.